Cite this as: Aspöck, E., Eichert, S., Theodoridou, M., Felicetti, A. and Richards, N. 2023 Integrating Data on Early Medieval Graves: Mapping the THANADOS database to the ARIADNE infrastructure with the Mortuary Data Application Profile, Internet Archaeology 64. https://doi.org/10.11141/ia.64.11
The ARIADNE Ontology is a modular ontology designed to describe the datasets that are being aggregated in the ARIADNEplus infrastructure (Richards et al. 2020). The ARIADNEplus Ontology is structured into sub-ontologies, including a catalogue, AO-Cat, providing appropriate classes and properties to describe the ARIADNE Catalogue, and several Application Profiles (APs), that provide classes and properties to describe the different sub-disciplines and specialisms of archaeology. Branches of this ontology have been used to encode the mortuary data presented here and to model it on various levels for the pure description, at collection level, of datasets and their structure, down to their content and specific items. The ontology is designed to achieve integration and establish interoperability among aggregated data and is able to provide layers of query across the integrated semantic graph it implements.
The CIDOC CRM is a formal ontology designed to facilitate the integration, mediation, and interchange of heterogeneous cultural heritage information. It was developed by interdisciplinary teams of experts, including those from computer science, archaeology, museum documentation, history of arts, natural history, library science, physics, and philosophy, under the aegis of the International Committee for Documentation (CIDOC) of the International Council of Museums (ICOM). The CIDOC CRM contains the most basic relationships to describe what happened in the past at a human scale, i.e., people and things meeting in space-time, parts and wholes, use, influence, and reference (Doerr et al. 2015 444).The CIDOC CRM has also been implemented in various archaeological case studies, such as those discussed by Masur et al.(2014).
Archaeological subdisciplines produce different data types that represent the knowledge of the field. The ARIADNEplus Application Profiles (APs) cater for the specific requirements of the knowledge of the whole field. APs are based on the core CIDOC CRM ontology and the family of compatible models. They were developed by archaeologists in collaboration with ontology experts and should provide examples of mappings that ideally represent knowledge about the individual subdomains. APs are sets of appropriate classes and properties, policies and guidelines that, in the context of ARIADNE, support mappings of archaeological data to the infrastructure.
Mortuary archaeology consists of a series of research activities and analyses carried out either directly on mortuary evidence (archaeological evidence containing human remains or contexts that are interpreted to relate to the disposal of the dead), and/or on documentation and finds (human remains, objects, samples) from such contexts. Mortuary evidence provides information firstly about ways of disposal of the corpse and past funerary practices (e.g. Weiss-Krejci 2011); secondly, mortuary data is used as a proxy for many aspects of past societies, such as identities, migration, social composition, landscape and memory, power, beliefs, art and craft, technologies (e.g. Hinton et al. 2011; Dickinson 2011).
Research questions and approaches to the analysis of mortuary data have changed in line with the development of archaeological thinking and they also vary according to the archaeological period and types of mortuary practices. Mortuary archaeology is closely related to the fields of human osteology and other science-based analyses of human remains. Recently, the use of bioarchaeological approaches that study human remains in their archaeological context are increasingly gaining ground. This is a significant progression from earlier studies, where analysis of archaeological and human skeletal evidence were carried out more or less separately. In earlier studies mortuary evidence was perceived as more or less static deposits that represent 'closed finds' (sets of artefacts that had been buried at the same time). They were imperative for the development of archaeological typologies and chronologies (Montelius 1903). Recently, interest in the formation processes of mortuary deposits as well as their potential multi-staged processes, including various types of post-depositional interventions, has been increasing and led to a more dynamic perception of their nature (e.g. Weiss-Krejci 2011; Aspöck et al. 2020). All these issues are reflected in the available mortuary data.
Early medieval cemeteries are found across Europe and comprise tens or hundreds of graves where commonly the body was buried shortly after death, usually in an organic container and frequently lavishly furnished with artefacts (e.g. Halsall 2010). Because of the high degree of similarity of the evidence, the structure of the resulting data is similar (Figure 3). However, because of changes in archaeological focus the granularity of the data varies widely. For example, earlier datasets may be focused on artefact description and neglect contextual information, such as positioning of the human remains and human osteological data, while more recent datasets may include a very detailed description of the latter.
In this article we will describe the development and application of standards to increase interoperability of data from archaeological mortuary contexts using early medieval cemetery data as a case study. More specifically, we will present the development of the ARIADNE Mortuary Data Application Profile (Aspöck et al. 2022), which is an extension of the ARIADNE project ontology (Richards et al. 2020) and based on the CIDOC CRM (Doerr 2003). Together with other APs it provides the basis for cross-querying datasets from different providers via the ARIADNE infrastructure. Our case study is provided by the integration of the THANADOS archaeological and anthropological data to the ARIADNE infrastructure using the classes and properties of the Mortuary Data AP.
Mortuary data may result from several types of archaeological and non-archaeological observations (e.g. geophysical prospection, fieldwalking, metal-detecting, excavation). The basis for the more detailed datasets that we are dealing with here is generally excavation, followed by a post-excavation phase where finds and documentation are analysed and interpreted for publication and further analysis as part of future projects. The workflow involves the participation of different actors with specific roles and the use of a range of devices and software. All these elements are considered relevant for the definition of adequate metadata for these datasets. Datasets are archived at different stages of the scientific workflow and may be reused by experts to answer new research questions and create syntheses - each leading to the creation of new datasets:
Type 1 - datasets that are generated in the field. Generally, mortuary evidence may be identified and documented during different types of archaeological and non-archaeological activities. Archaeological excavation involves excavation and documentation of archaeological evidence that contains human remains and features relating to the disposal of the dead (e.g. pyres, buildings). During fieldwork the exact place and context of finds and features is recorded before finds and samples are collected from their original archaeological context. The resulting data may be deposited in an archive, with little or no additional analysis. Some analysis, such as parts of taphonomic investigations, may have already been carried out in the field (Duday et al. 1990).
Examples: These types of dataset would typically come from excavation companies, or governmental organisations recording excavation activities; ARIADNEplus partner datasets that contain field data from cemetery excavations are: ARUP (AMCR) in the Czech Republic, the Hungarian National Museum Database, and the UK's Archaeology Data Service (ADS).
Type 2 - datasets that are generated during analytical workflows after the completion of fieldwork (post-excavation). Post-excavation analysis typically involves work that is carried out by archaeologists plus a range of other specialists. Human remains will be analysed by a biological anthropologist, the assessment of artefacts will be done by finds specialists and a whole range of scientific analyses may be carried out in laboratories (e.g. radiocarbon dating, stable isotope and aDNA analyses). Other types of specialist analyses include that of animal bones, plant remains, textiles, soil micromorphology, sediments, etc. Cemetery analysis typically involves distribution mapping of certain traits of graves and may also involve spatial and statistical analysis of the results (e.g. using GIS). Digital information is generated as a result of each analysis, resulting in a rich dataset that will ideally be deposited in a data archive and, which is frequently accompanied by publication of written account(s) (analogue and digital books and articles). Such datasets typically concern mortuary data from one site. They often also include structured data and written reports.
Examples: rich datasets, usually from individual cemeteries, can be found in datasets available from ARUP (AMCR e.g. https://digiarchiv.aiscr.cz/id/C-TX-201502523), ADS (e.g. Cuxton Anglo-Saxon Cemetery https://doi.org/10.5284/1044805), the Hungarian National Museum Database (e.g. https://archeodatabase.hnm.hu/hu/node/1617 ), and E. Fentress (Villa Magna Material http://archaeologydata.brown.edu/villamagna/the-human-skeletal-remains/.
Type 3 - Structured datasets that synthesise and aggregate mortuary data. Aggregated mortuary datasets contain structured data that was extracted from datasets of above-mentioned types 1 and 2 and from publications (articles, books, grey literature). They may also be integrating other structured datasets that synthesise information (type 3). Such databases typically aim to integrate information to provide an overview of a certain period and/or region, or data that may have been collected to answer a specific research question.
Examples: THANADOS and ZBIVA provide detailed data on early medieval cemeteries. Examples of datasets compiled to answer specific research questions include a database on Anglo-Saxon Graves and Grave Goods of the 6th and 7th centuries, held by ADS https://doi.org/10.5284/1018290) as well as a dataset of features of reopened graves curated by DANS (e.g. In touch with the dead https://easy.dans.knaw.nl/ui/datasets/id/easy-dataset:66658).


Datasets of above types 1 and 2 represent the ARIADNE resource type category 'Fieldwork archive'. Their integration into the ARIADNE infrastructure required only collection-level description (e.g. geographical extent, date range and subjects) for which the properties and classes of the AO-Cat were sufficient. Datasets of type 3 fall into the ARIADNE resource type category 'Site/monument'. While the standard AO-Cat properties also suffice for collection-level description here, we wished to achieve item-level integration of such datasets, which required usage of the CIDOC CRM and its extensions. The ARIADNE Mortuary Data AP presents the classes and properties that we recommend for the mapping of structured mortuary data for integration (Aspöck et al. 2022.
The dataset 'In Touch with the Dead: Early Medieval Grave Reopenings in the Low Countries' by Van Haperen (2017a) served as a case study for the development of the AP. It is held at the DANS repository and includes a relational database on eleven early medieval cemeteries in the Low Countries. The data were compiled for Van Haperen's PhD thesis on reopened early medieval inhumation graves (2017b) at Leiden University. The database includes basic information on all 'context' types (inhumation and cremation graves, animal graves, pits, ditches, stray finds), human remains and grave goods (Figure 3). In addition, it contains detailed information on the different types of post-depositional interventions that were the focus of investigation. It consists of 7 main tables and 29 reference tables that, for integration into the ARIADNE infrastructure, were mapped using the 3M mapping tool.
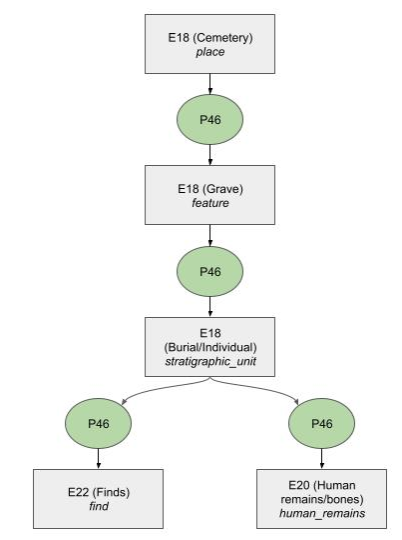
The ARIADNE Mortuary Data AP is presented according to the typical entities of a cemetery database (Figure 3). The top category would be a description of the site, i.e. the cemetery or other site type that contains mortuary deposits. The site typically consists of multiple features - in the case of early medieval cemeteries the majority would be inhumation graves, but there are also cremation graves, ditches, pits and other features. The mortuary deposit describes the deposit (in our test data this was not a separate entity, since in many cases the description of the human remains and finds was added directly to the feature, which, however, creates problems as soon as there is more than one deposit within a grave). Finally, there is a description of all finds that were part of the deposit (human remains, artefacts, animal remains, samples).
To make the AP easier to use, we structured the mappings for each entity according to the main ARIADNE parameters: Where? When? What? Figure 3 shows that these questions apply to all levels of these datasets. From the site-level through to the individual finds we record information on: the date; the spatial properties (location of a site; position of a feature inside a site; the position of the deposit and of the finds - in relation to the feature and the buried body); and describe what was found, frequently using typologies of cemeteries, graves, containers and finds.
For a semantically rich description of mortuary deposits, i.e. more on the 'What?' that would enable integration at the item-level, the ARIADNEplus ontology was not sufficient and in addition we used classes and properties from the CIDOC-CRM base model (Doerr 2003), version 6.2.1 and its compatible extensions CRMsci - Scientific observation model, version 1.2.2 and CRMarchaeo - Excavation model, version 1.4.1.

Assignment of types, dates and other properties are interpretations that depend on the views of the person who created the data, as well as the methods that were used. Hence we suggest the use of an assignment event (E13_Attibute_Assignment) to acknowledge this (Figure 3). A cemetery database may contain multiple assignment events, if information was compiled from different sources:
P140i_was_attributed_by -> E13_Attribute_Assignment -> P14_carried_out_by -> E21_Person = "Name"
E27_Site is defined as relatively immobile material items and features at a particular location and applies to archaeological sites (Figure 4). To make a cemetery database visible in the ARIADNE portal, it has to be mapped to the AO-Cat - hence for the THANADOS mappings (see below), site has been mapped as an AO_Collection too.
On the collection level, data for each site/cemetery have been mapped as ARIADNE site and monuments data. This includes information about the name, identifier, geographical extent and its date range (expressed via the ARIADNE properties has_title, has_identifier, has_space_region, has_time_interval) and in most cases there is also a classification of the specific site type (e.g. cemetery). The site type and further specifications of the 'What?' – i.e. information on the type of cemetery or other type of information – are mapped as has_type -> AO_Concept. The original vocabulary of the database was integrated into the infrastructure via the property 'has_native_subject', which means it can later be queried via the ARIADNE interface. Native site types were mapped to the Arts and Architecture Thesaurus (AAT). All the basic ARIADNE questions apply to all levels of the data in early medieval cemetery databases, so the same mappings also apply to features, individual deposits and finds (see below).
We mapped Feature information as an 'A8_Stratigraphic_Unit', as on the most general level these are physical features
that archaeologically consist of A2 Stratigraphic Volume Units and A3 Stratigraphic Interfaces. Information about
the name, identifier, geographical extent, date range and type of feature are mapped to the same type of information
relating to a site. For the THANADOS mappings we decided to make the features AO_Collections too:
AO_Collections -> is_part_of -> AO_Collection (the site, see above).
Something that would typically be recorded is the size of a feature (Figure 4), as grave size is commonly seen as a factor when assessing the investment in the burial and hence reflecting social status during the lifetime of the individual interred.
Mortuary deposits are A8_Stratigraphic_Units and were also mapped as AO_Collections that are part of features. Usually, large finds such as coffins or other furniture related to an individual burial are described as part of this entity. Measurements of a coffin or other grave furniture may be mapped in the same way as the size of the grave pit, see above (Figure 4). For example, a stratigraphic unit contains an object of the type 'coffin'; that is a stratigraphic volume unit with length and width dimensions.
The class AO_Object is a subclass of E18 Physical thing and it allows usage of all AO-Cat properties. Depending on the type of find, artefacts are mapped as E22_Man-made-Object or E20_Biological_Object (human remains, animal remains). For the THANADOS mappings we decided (in order to align with the portal) to map all finds to AO_Individual_Data_Resource. The 'When?' and 'Where' questions are mapped in the same way as the entities described above. Frequently there is information on the material or number of the finds (Figure 4).
By analogy with assignments by archaeologists (e.g. attribution of find types by a finds specialists) all data on human (or animal) remains were also attributed to a person via an attribute assignment (E13). All properties attributed by the biological anthropologist, such as sex, age at death, pathologies, preservation, position of the skeleton are mapped as types:
has_type ->AO_Concept -> has_type -> E55_Type ['Sex', 'AgeAtDeath', …]

The Anthropological and Archaeological Database of Sepultures (THANADOS), is an interdisciplinary project that combines the fields of archaeology, biological anthropology, and digital humanities. It is based at the Natural History Museum Vienna (NHMW) working in collaboration with the Austrian Archaeological Institute (OeAI) and the Austrian Centre for Digital Humanities and Cultural Heritage (ACDH-CH) of the Austrian Academy of Sciences (OeAW).
Archaeologists and biological anthropologists typically publish their grave finds and cemetery research in the form of a catalogue consisting of descriptive texts, categorisations, spatial and temporal data, and graphic representations. In the past, publications were in print, but now there is a growing trend towards electronic publications, commonly in PDF format (see above, datasets type 2). Digital databases attached to publications are rare and often lack standardisation. So the data provided, whether in print or digitally cannot be used 'out of the box' for further analyses. To make sites comparable, existing data must be standardised or digitised and brought into a uniform format (see above, dataset type 3). The creation of a structured dataset on early medieval graves in Austria was one of the main aims of THANADOS.
The first phase of the project collected data on cemeteries and burial sites dating from Late Antiquity (approximately 400 CE) to the early High Middle Ages (around 1100 CE). It concluded by the end of 2021 with all Austrian cemeteries from this period collected and digitised. Currently (October 2023), the THANADOS web portal provides open access to data from 563 cemeteries, 5363 graves containing 5643 individuals and 11,555 finds as well as 6169 osteology datasets. As a next step, the temporal and geographical scope of sites presented in THANADOS will be expanded. In addition to information about the sites, presented in the form of a catalogue, THANADOS also provides state of the art data visualisations, options to query the data and download functions. All datasets are provided with references to the original publication and citation suggestions.
The 'archaeological' data model used by THANADOS is mainly based on the way archaeologists document their data from cemetery excavations (see also Figure 3). The data are organised into four levels, starting with the site itself, which serves as a container for all subunits. The next level focuses on the archaeological features observed at the site, such as graves, which then contain information on related stratigraphic units, such as buried individuals (referred to as 'burials'), which in turn contain data on physical objects found, such as grave goods. This hierarchical structure is evident in traditional publications on burial sites. The boundaries between these levels may be defined by the archaeologists, based on their observations during excavation. For example, a temporal boundary may be drawn between a prehistoric and a medieval cemetery found on the same site. The distinction between characteristics of graves as features and their contents, such as what belongs to the 'burial' and what is part of the grave fill, may also depend on the archaeologists' interpretation. The level of burial can contain further subunits, such as finds, individual bones or osteo-archaeological data. Overall, this hierarchical structure reflects a relational data model that can commonly be observed in the documentation of graves.
To implement the archaeologically specified data model and technically realise it for the THANADOS project, the project team developed and adapted the open-source software OpenAtlas (Watzinger 2019). Their goal was to digitise existing information according to best practice standards while also fulfilling the FAIR principles, with a focus on integrating or aggregating the data into existing European or international infrastructures (Meghini et al. 2017). The data are stored in OpenAtlas using classes and properties of the CIDOC CRM (Eichert 2021). Technologically, the OpenAtlas/THANADOS team uses a PostgreSQL/PostGIS database, and the available information is recorded in as much complexity as necessary and, at the same time, as simple as possible through a user-friendly interface (Eichert 2021).
THANADOS uses its own vocabulary (https://thanados.net/vocabulary) to classify and categorise its data. In order to enhance the comprehensibility, compatibility, and interoperability of the data, THANADOS entities and its vocabulary link to existing gazetteers, vocabularies, thesauri, and other reference systems. These include Geonames for spatial relations, the Getty Art and Architecture Thesaurus (AAT) for functional typology, PeriodO for chronological periods, the WHO International Classification of Diseases (ICD) for diseases and pathologies, and Wikidata as a general vocabulary. To specify the connections between an entity or a classification in THANADOS and an external reference or vocabulary entry, the SKOS terms 'exact match' and 'close match' are used.
Data in OpenAtlas can be exposed through various formats, such as JSON-LD using the Linked Places or Linked.art LOUD format, XML, RDF, Turtle, CSV, and more through a built-in API. THANADOS and OpenAtlas mainly deal with historical and archaeological sources, which often contain spatial and temporal inaccuracies and uncertainties. To address this issue, a concept is used that represents up to 100% certainty with varying precision. The concept is based on the GeoJSON-T model and uses multiple time periods to document a site's chronological framework. For example, a cemetery that was occupied from the first half of the 8th century to the 11th century would be documented with two time periods: an earliest and latest start date as well as an earliest and latest end date.
Similarly, spatial information is documented using point, polyline, and polygon geometries. For instance, a precise location of a single find would be documented with a point coordinate, whereas a precisely measured outline of a church cemetery with a polygon would be classified as a 'shape'. When the exact location of a site is unknown, a polygon can still be used to document the extent with 100% certainty, and it would be classified as an 'area' (Eichert et al. 2016).
Aside from the collection of the data, their presentation in human 'processable' formats was an important focus for the project. To present and disseminate these data the THANADOS web application was developed and has been publicly accessible online since 2019, based on open-source web technologies including Python, Flask, HTML 5, JavaScript, and CSS. The application retrieves data from the database and presents it on the client side using JSON or GeoJSON formats. It uses Bootstrap 5 as the framework for the responsive interface, and each location or entity has its own landing page with a persistent URL that contains all available information on the entity and links to other entities. The landing pages also include an interactive burial ground plan and a dashboard that visualises statistical data using open-source JavaScript libraries such as charts.js and D3.js. The cartographic view is enabled by the JavaScript library Leaflet.js, which offers various GIS functionalities and query options. The application allows intersite comparisons and global searches, and results are output in tabular form and on a map. All data can be downloaded in CSV, GeoJSON, and image formats, and all results and information generated by THANADOS are available as open data under the Creative Commons Attribution International 4.0 licence. Third-party information or differently licensed data are marked separately, and the authors of the original publications are cited, which should also help to disseminate their results and increase bibliometric impact. The FAIR Data Object Assessment Metrics (https://www.f-uji.net/) currently results in a FAIR level of 'moderate' with 56%.

An API provides various output formats for the respective entities. In order to harvest data for ARIADNEplus an XML representation of each cemetery with its graves, human remains and finds was developed. To keep the data aligned, the API can also be used to list all cemeteries and sites that have been updated since a certain date, to update the respective entities.
The mapping of THANADOS xml to AO-Cat and the Mortuary Data Application Profile was undertaken using the 3M Mapping Memory Manager. It consists of four main mapping tables corresponding to the four main entities of THANADOS: place (cemetery), feature (grave), stratigraphic unit (burial) and artefact (find). At a high level, the mapping of THANADOS to AO-Cat allows the resources to be visible in the ARIADNEplus portal, integrated with the millions of other resources. For this purpose, place (cemetery), feature (grave) and stratigraphic unit (burial) are mapped to AO_Collection while artefact (find) is mapped to AO_Individual_Data_Resource. Both AO_Collection and AO_Individual_Data_Resource are subclasses of E73_Information_Object and describe the digital resources of the ARIADNE Research Infrastructure. These digital data resources refer to the actual resources modelled as E27_Site, A8_Stratigraphic_Unit, E22_Man-Made_Object and E20_Biological_Object. The mappings of the THANADOS entities to AO_Cat, Mortuary AP and the corresponding ARIADNE_subjects are shown in Table 1 and in Figure 7, as implemented in 3M.
Publishing THANADOS data to the ARIADNEplus portal also required mappings of the THANADOS vocabularies to the AAT and mappings of the THANADOS periods to PeriodO.
| THANADOS | AO_Cat | Mortuary AP |
ARIADNE subject |
| Place | AO_Collection | E27_Site | Site/monument |
| Feature | AO_Collection | A8_Stratigraphic_Unit | Burial |
| Stratigraphic_unit | AO_Collection | A8_Stratigraphic_Unit | Burial |
| Artefact | AO_Individual_Data_Resource | E22_Man-Made_Object | Artefact |
| Human remains | AO_Individual_Data_Resource | E20_Biological_Object | Burial |


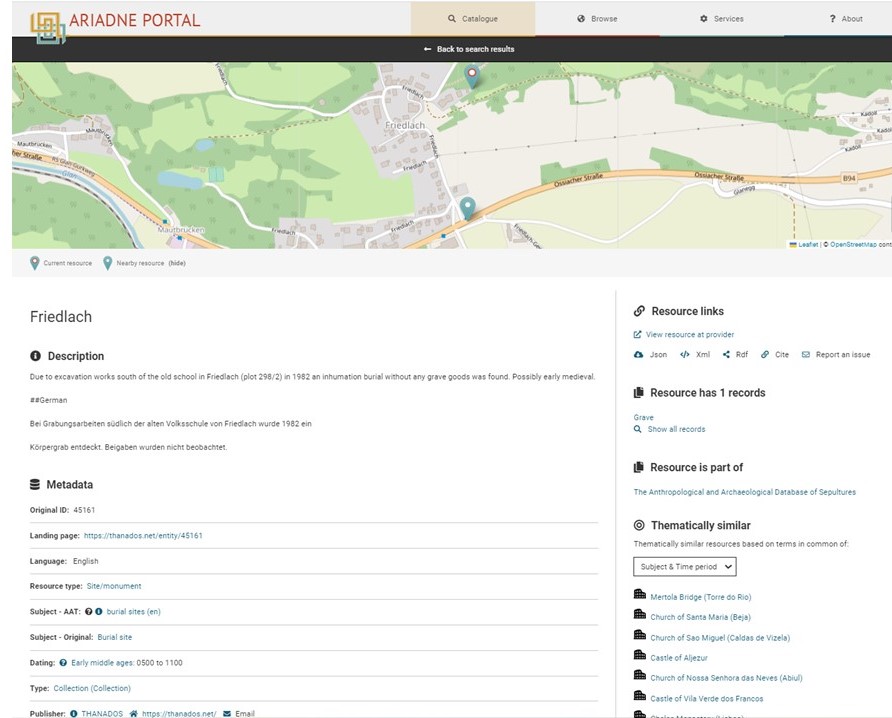
Figure 8 presents the top level collection of THANADOS as presented on the ARIADNEplus portal. It includes 462 sub-collections that correspond to the burial sites. Every burial site may also include graves that in turn include burials and/or artefacts. An example of the burial site of Friedlach is presented in Figure 9.
Furthermore, in order to assess the suitability of the models for integrated queries, we ran indicative queries on https://graphdb.ariadne.d4science.org/sparql, which is the SPARQL endpoint of the ARIADNEplus Knowledge Base that includes the THANADOS data. Unfortunately, there were no other relevant datasets yet available in the knowledge base but it shows as a proof of concept that if the Mortuary AP is applied consistently, integration is feasible. Table 10 presents the questions, the respective SPARQL queries and the results.
Namespaces used:
| Query | SPARQL | No. of results / Publishers |
|---|---|---|
| Find all graves of juvenil | SELECT DISTINCT ?resource ?resourceL ?Height ?Width WHERE { { ?resource aocat:has_ARIADNE_subject ?concept. ?concept skos:prefLabel "Burial"@en. ?resource aocat:has_native_subject/skos:prefLabel "Juvenile"@en; rdfs:label ?resourceL. } } | 190 from THANADOS |
| Find the width and height of graves of juvenil | SELECT DISTINCT ?resource ?resourceL ?Height ?Width WHERE { { ?resource aocat:has_ARIADNE_subject ?concept. ?concept skos:prefLabel "Burial"@en. ?resource aocat:has_native_subject/skos:prefLabel "Juvenile"@en; rdfs:label ?resourceL. ?resource aocat:is_part_of ?grave. optional {?grave crm:P43_has_dimension ?dimW. ?dimW crm:P2_has_type/skos:prefLabel "Width"@en. ?dimW crm:P90_has_value ?Width.} optional{ ?grave crm:P43_has_dimension ?dimH. ?dimH crm:P2_has_type/skos:prefLabel "Height"@en. ?dimH crm:P90_has_value ?Height.} } } | 190 from THANADOS 149 resources have height specified 103 resources have width specified 93 resources have both width and height specified |
| Find Female skeletons where the height has been documented | SELECT DISTINCT ?resource ?resourceL ?Height ?Width WHERE { { ?resource aocat:has_ARIADNE_subject ?concept. ?concept skos:prefLabel "Burial"@en. ?resource aocat:has_native_subject/skos:prefLabel "Female"@en. ?resource aocat:has_native_subject/crm:P2_has_type/skos:prefLabel "Body Height"@en; rdfs:label ?resourceL. }} | 68 from THANADOS |
| Find which types of artefact were buried with juvenil | SELECT DISTINCT ?type WHERE { { ?resource aocat:has_ARIADNE_subject ?concept. ?concept skos:prefLabel "Burial"@en. ?resource aocat:has_native_subject/skos:prefLabel "Juvenile"@en; rdfs:label ?resourceL. ?resource2 aocat:is_part_of ?resource. ?resource2 aocat:has_native_subject/skos:prefLabel ?type. } } | 111 artefacts from THANADOS |
| List all graves that have been ‘Disturbed’ | SELECT DISTINCT ?resourceL WHERE { { ?resource aocat:has_ARIADNE_subject ?concept. ?concept skos:prefLabel "Burial"@en. ?resource aocat:has_native_subject/skos:prefLabel ?nsL. FILTER (contains(?nsL,"Disturbed") ) ?resource rdfs:label ?resourceL. } } | 291 from THANADOS |
Mapping datasets to ontologies is a way to increase their interoperability and their potential for reuse. However, how to map data may often be ambiguous and down to the opinion of individual researchers (Katsianias et al. 2023). Different 'domain-experts' may not agree on how best to represent the knowledge of their field or how to interpret the meaning of classes and properties if scope notes are difficult to comprehend. The ARIADNEplus answer to this problem was the creation of APs to provide exemplary mappings that other researchers can use for orientation.
Early medieval cemeteries predominantly consist of inhumation graves that show a high degree of similarity in their construction. Consequently, the mortuary data from these cemeteries is organised in a very similar way, lending itself to large-scale comparison and as a test case for the creation of an AP for mortuary data. However, the creation of the mortuary data AP has shown that mapping to an ontology can reveal inconsistency in the data organisation and hence contributes to a more stringent structuring of information in future data collections.
The first version of the ARIADNEplus Mortuary Data AP was tested during the integration of the THANADOS anthropological and archaeological database of sepultures. The hierarchical structure of CIDOC CRM and the mechanism of inheritance allowed the alignment of the THANADOS, AO-Cat and Mortuary AP schemata without any complications. THANADOS follows a more general approach, mapping place (cemetery), feature (grave) and stratigraphic unit (burial) to E18 Physical Thing. According to the Mortuary AP, cemetery is mapped to E27 Site while grave and burial are mapped to A8 Stratigraphic Unit. Both E27 and A8 are subclasses of E18 so there is no violation of rules during the mapping.
The CIDOC CRM ontology contributes to research on early medieval graves and increases the potential for reuse of early medieval cemetery data, as it enables querying across datasets – information on graves and cemeteries that were not contained in the same source can be queried. It provides an example of how archaeological data can be aggregated and integrated across multiple providers.
The research leading to these results has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement no. 823914.
The THANADOS database was funded by the go!digital NextGeneration programme of the Austrian Academy of Sciences (GDND 2018 039).
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service. Help sustain and support open access publication by donating to our Open Access Archaeology Fund.
 Home
Home