Cite this as: Hiebel, G., Danthine, B., Peralta Friedburg, M. and Scherer-Windisch, M. 2023 Prehistoric Mining Data: How to create Open Data from archaeological research for the ARIADNE community and beyond, Internet Archaeology 64. https://doi.org/10.11141/ia.64.8
The interdisciplinary Research Center HiMAT (History of mining activities in the Tyrol and adjacent areas, University of Innsbruck) investigates mining history from prehistoric to modern times using an interdisciplinary approach. One of the projects carried out at the research centre was the multinational DACH project 'Prehistoric copper production in the eastern and central Alps' (FWF I 1670-G19), which ran from 2015 to 2018 (Goldenberg 2021). For the specific geographical region of the project that was covered by the University of Innsbruck (Figure 1), the data transformation to open and reusable data was investigated in a separate Open Research Data pilot project from 2019 to 2021 (Hiebel et al. 2019). The methodological approach used the FAIR principles (Wilkinson et al. 2016; FORCE11 2019) to make data Findable, Accessible, Interoperable and Reusable. In the following sections we want to show how the archaeological reports for the Austrian Federal Monuments Office were transformed. The first step was to change the file formats where necessary and store the documentation on Zenodo and Google Drive. In the second step the information was extracted and conceptually represented with CIDOC CRM and its extensions (Doerr 2003; Bekiari et al. 2022) and implemented in RDF, a semantic web standard for data interchange on the Web. RDF is also used by ARIADNE, the European Union Research Infrastructure for archaeological resources (Niccolucci et al. 2013) to bring archaeological resources together in the ARIADNE Portal. The methodology of this information extraction and RDF creation with its various steps are the focus of this article. The methodology presented is exemplified here with concrete archaeological data from the Federal Monuments Office documentation but it can be applied to a variety of domains and data sources and was also used to create the resources for the ARIADNE Portal. The single steps to follow together with sample data are elaborated in a separate 'RDF Creation Pipeline', with examples from other domains. A short overview of the pipeline is given in Section 5.
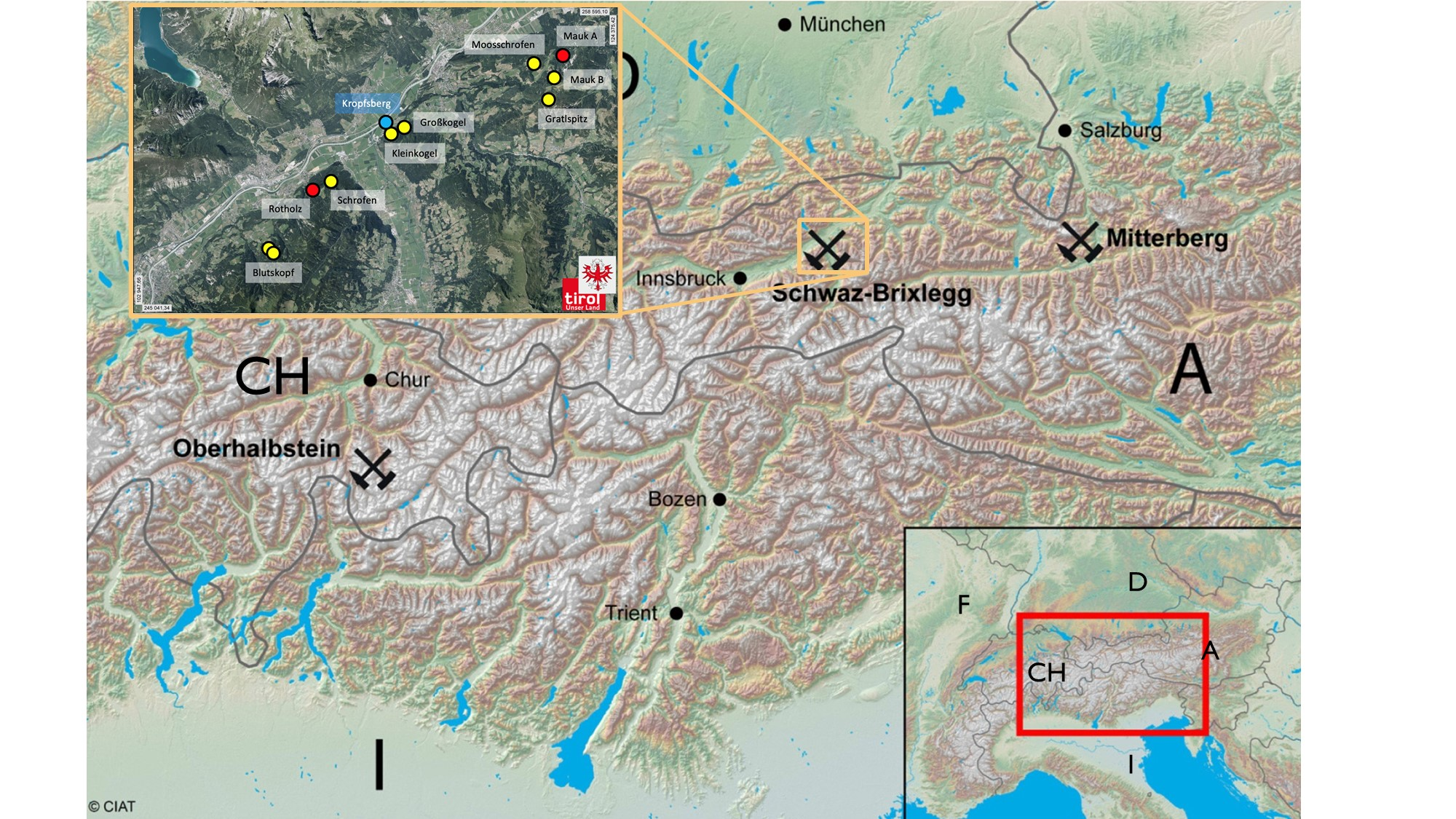
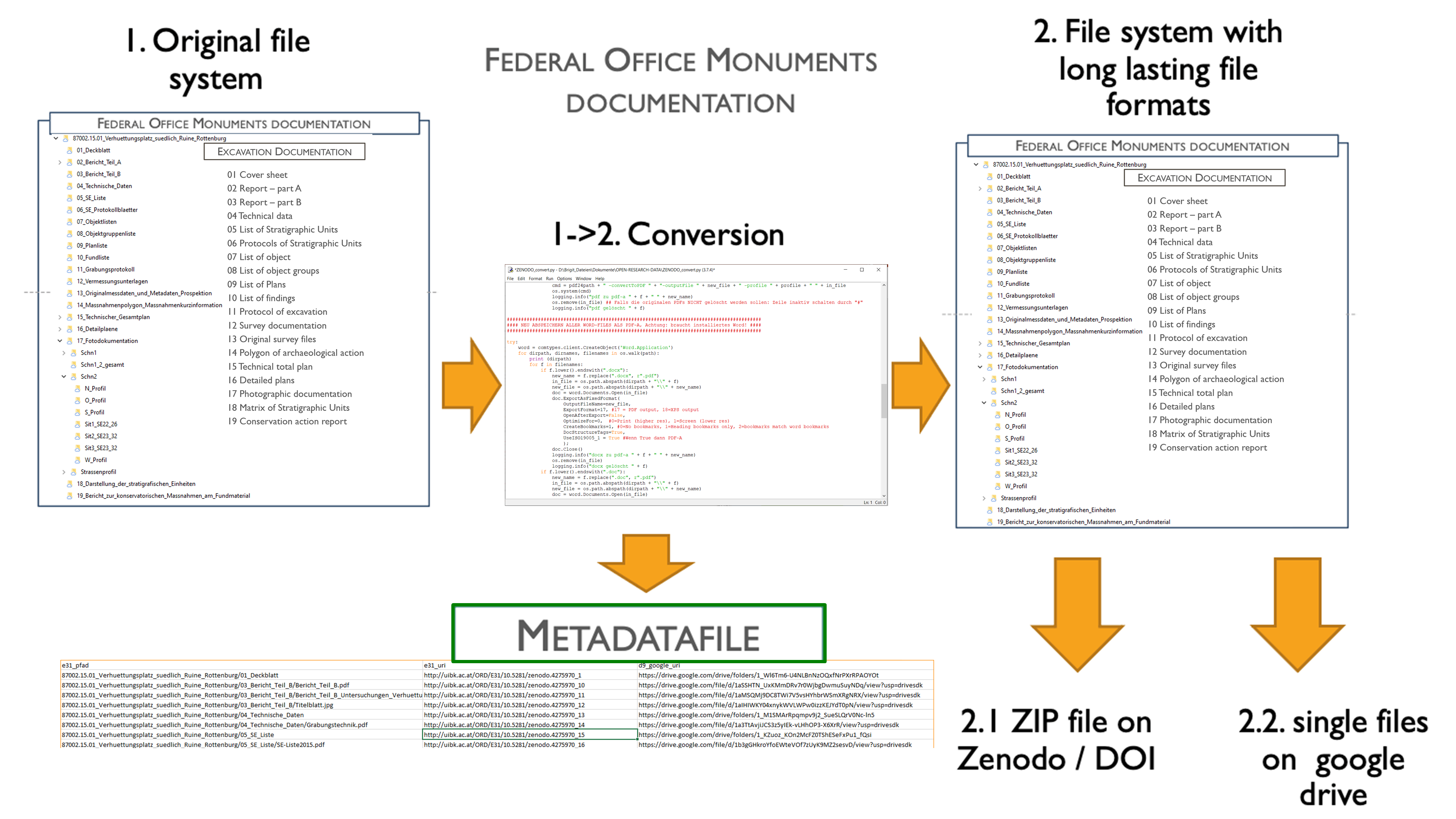
Every archaeological investigation in Austria has to be documented in accordance with the requirements of the Austrian Federal Monuments Office. In the case of the DACH project 'Prehistoric copper production in the eastern and central Alps', six reports on field surveys and excavations were documented according to these guidelines. They define in detail which reports, lists, photos and plans have to be created for prospections, excavations, stratigraphic units, finds, archaeological objects and groups. Figure 2 shows the categories and directory structure of the documentation as defined by the Federal Monuments Office. The left side illustrates an example for the documentation of an excavation activity at the smelting site '87002.15.01 Verhüttungsplatz südlich der Ruine Rottenburg'. The site was documented in 336 files with a total size of 5.34 Gb. For example, the documentation of a survey on mining sites (underground mines and pits) in the fahlore district of Schwaz-Brixlegg comprised 244 files with a total size of 1.33 Gb, documented under the folder '87007.15.01 Bergbaurevier Schwaz-Brixlegg'. For the excavation site and the fahlore district there are reports for three consecutive years, creating six reports that were further processed. The documentation contains various file formats such as MS Word documents for reports and lists, PDF documents containing scans of handwritten protocols, Autodesk .dwg or .dxf files for plans and .jpg images for photos and similar material.

In order to convert these formats into long-lasting file formats using the Archaeology Data Service (Archaeology Data Service 2019) and IANUS Guidelines (IANUS 2017), a Python program was written that also creates a metadata file with unique identifiers and the links to the location on Google Drive where these files are stored. The long-lasting file formats were converted to a zip file, using the original file structure, and put on Zenodo, a registered repository for long-term preservation of data. The process is illustrated in Figure 3. The reason for this double storage is that in Zenodo the file system has to be zipped and thus the single files are not directly accessible with a specific URI. As we then extracted and identified specific sites, structures, finds and stratigraphic units that were documented in specific files, we wanted to have access in a single documentation to the various individual reports that were created.
In our methodology there are six steps to create a knowledge graph in RDF from an existing source. First it is necessary to understand what entities are present in the source and which of them should be represented in the knowledge graph. Second, these entities should be represented in an ontology and the relevant ones selected at the level of detail to be available in the graph. As this representation determines the capabilities of querying the graph it makes sense to formulate research questions that can be answered by the graph. In particular, for archaeology the creation of a controlled vocabulary in a hierarchical structure is essential for the query capabilities. Third, the data has to be made available in a structured format such as spreadsheets or xml. After that, data transformations and linking are performed and unique identifiers have to be created before the final step of creating the RDF network. The next sections detail and illustrate these steps for the Federal Monuments Office documentation.
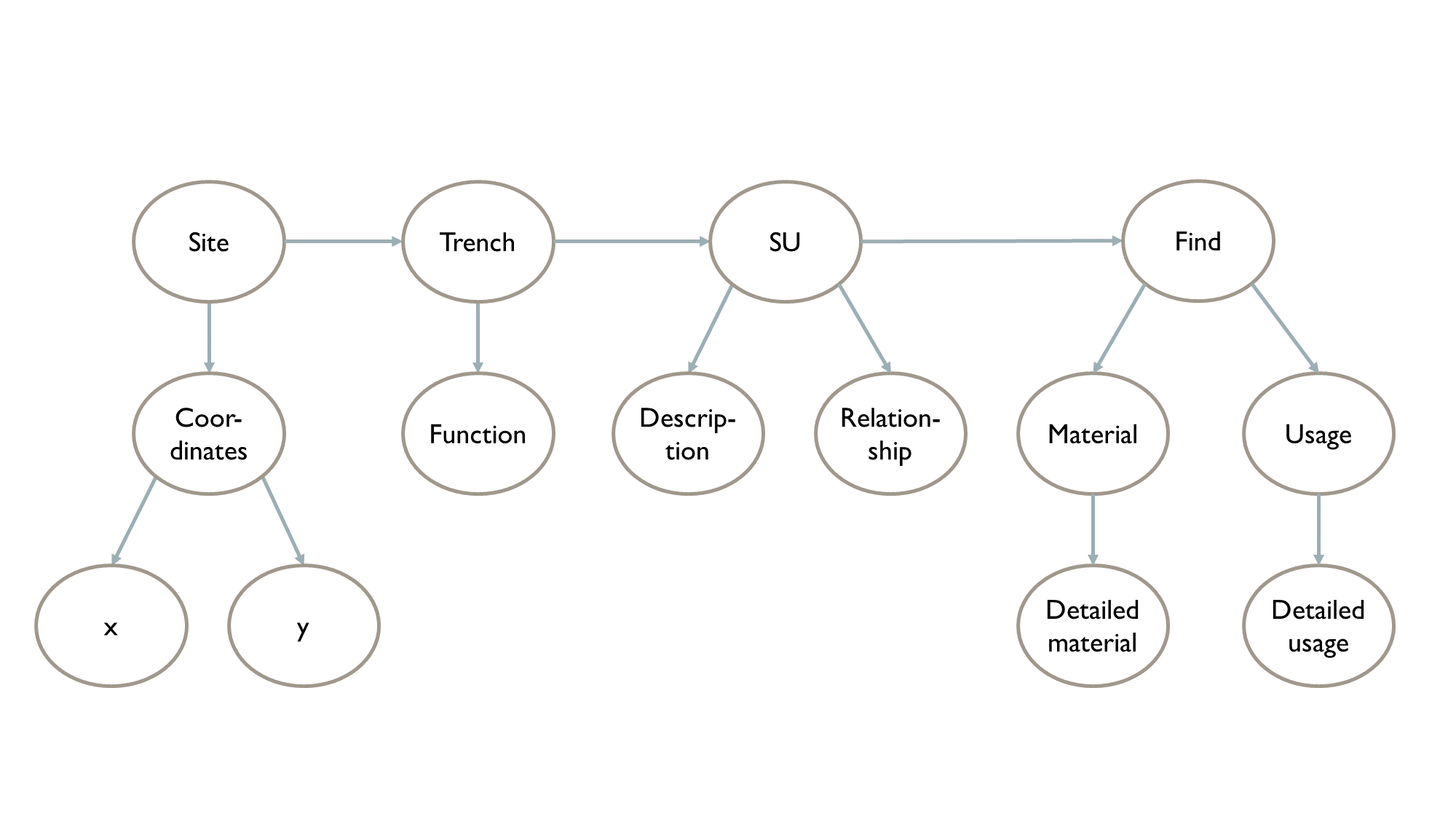
Archaeological sites associated with prehistoric mining have been documented. They have been encountered during field surveys and, if considered important enough, excavations have been carried out by opening trenches and using a stratigraphic excavation methodology that attempts to dig along stratigraphic units (SU), i.e. layers deposited at specific times by specific events. Finds may have been retrieved from the surface during field surveys or from the stratigraphic units during excavations. Figure 4 illustrates the documented entities and their relations.
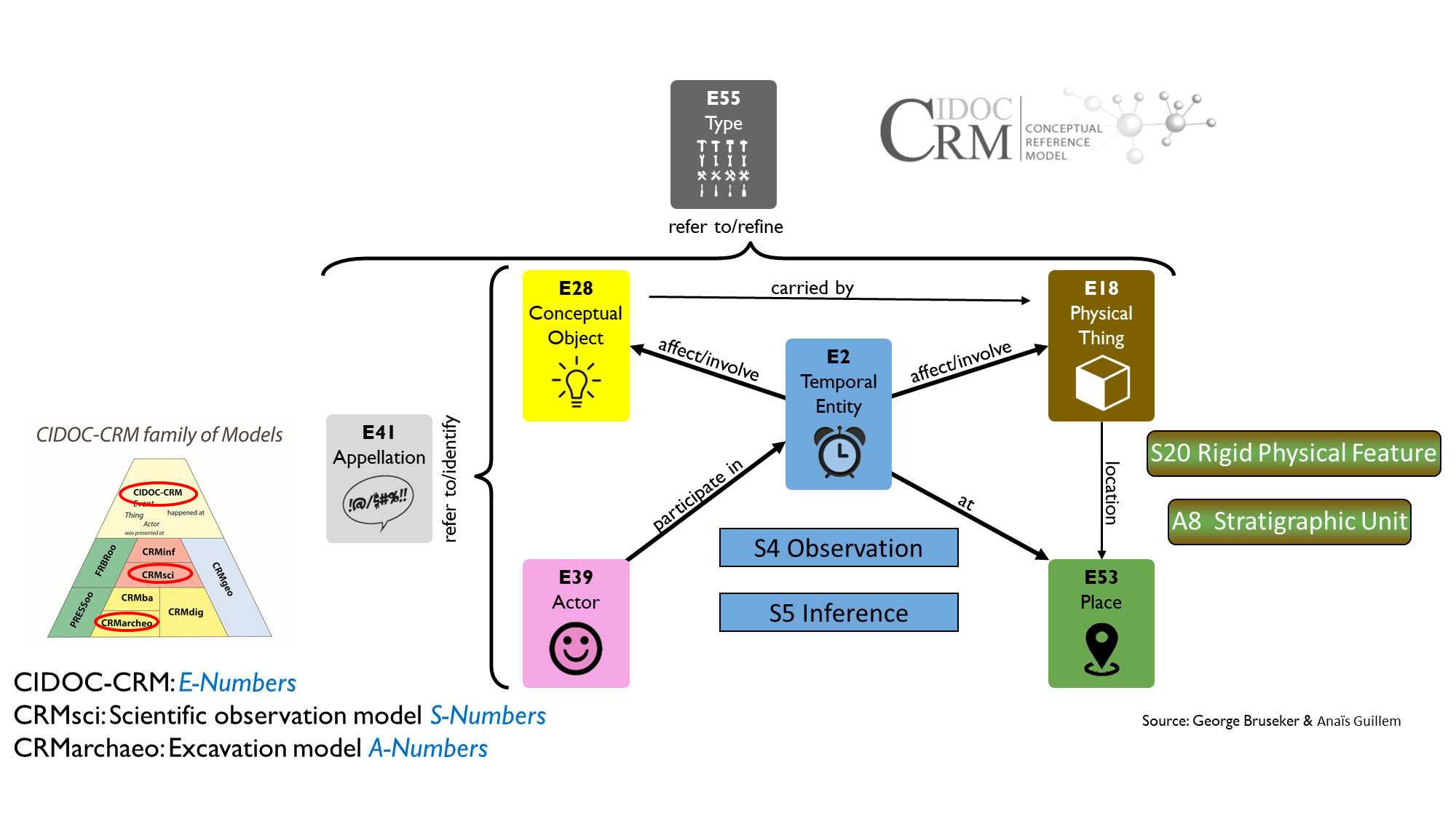
The CIDOC CRM ontology with its extensions was used for the creation of the metadata for the entities encountered in the previous step. The CIDOC CRM is an ISO standard for cultural heritage Information, which was adopted as the conceptual background by ARIADNE. Various initiatives have arisen to promote the understanding and dissemination of CIDOC CRM like the CRM game (Guillem et al. 2018). It was extended in the course of ARIADNE with CRMarchaeo (Doerr et al. 2016) to model archaeological excavations. It was built based on the official documentation requirements of different countries, including the Austrian Federal Monuments Office (Masur et al. 2014; Cripps et al. 2004). The extension CRMsci (Doerr et al. 2012) was used to model scientific observations. CIDOC CRM main classes and their basic relations are illustrated in Figure 5, together with the classes from CRMsci and CRMarchaeo employed to represent excavation-specific entities.
Archaeological sites and their investigated physical components such as trenches, stratigraphic units and finds are related with the properties illustrated in Figure 6. For all the physical components there are observations or inferences that are explicitly or implicitly stated in the documentation.
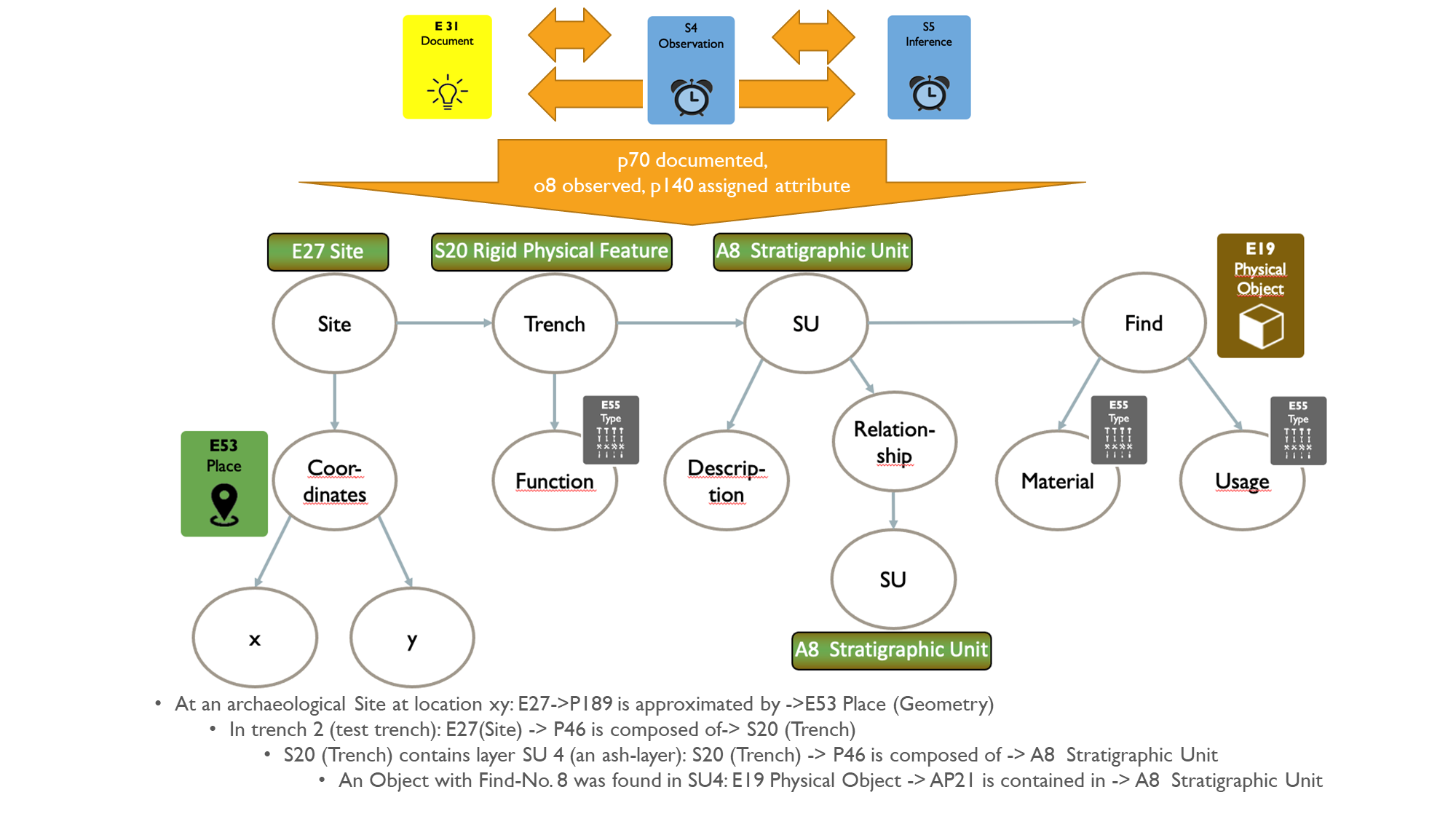
Within the ARIADNE community the different approaches to model and implement conceptual representations of archaeological excavations were explored in a workshop (Katsianis et al. 2022a), presented at the EAA 2022 in Budapest (Nenova et al. 2022) and are detailed in Katsianis et al. 2023. The results have been documented in the Archaeological Excavation Modelling Working Group report (Katsianis et al. 2022b).
An essential component to represent and query the knowledge contained in the documentation is a controlled vocabulary. Concepts specific to mining archaeology research were organised with the DARIAH Backbone Thesaurus (Doerr et al. 2022), a model for sustainable interoperable thesauri maintenance, developed in the European Union Digital Research Infrastructure for the Arts and Humanities (DARIAH). Simple Knowledge Organization System is a semantic web standard for sharing and linking knowledge organisation systems such as thesauri, taxonomies, classification schemes and subject heading systems and it was used to represent our vocabularies in RDF. One essential step to use the created data for aggregation in ARIADNE was to map the concepts used in the research data to the concepts of the Getty Art and Architecture Thesaurus and to PeriodO a collaborative gazetteer of chronological definitions that allows the association of a period name (e.g. 'Late Bronze Age') with a start and an end date, a corresponding geographic coverage, plus bibliographic reference through unique permalinks, e.g. http://n2t.net/ark:/99152/p0qhb66cjfs for the late Bronze Age in Austria from 3300 BP to 2800 BP. Getty vocabularies are an evolving hierarchical knowledge base of cultural heritage terms (Harpring 2022) that are available as Linked Open Data (LOD).
We used spreadsheets to collect terms with their translations, concept details and to create identifiers. Subsequently we placed them under the DARIAH Backbone Thesaurus hierarchy in mind-mapping software to organise the hierarchical order as shown in Figure 7. Concepts are handled together with their identifiers in a 'concept@identifier' string to facilitate the subsequent transfer to the database, as explained in Section 3.5. In order to unite different thesauri with their identifiers a thesaurus prefix is used, such as bbt for the DARIAH Backbone Thesaurus, aat for the Getty AAT or himat for the mining-specific concepts of the research centre HiMAT.

An essential quality of the methodology is to make it accessible to people without programming skills, as far as possible using available tools that they already know. From experience in the project 'A Puzzle in 4D - Tell el-Daba', where over 50 years of excavation reports have been digitised and metadata created (Aspöck et al. 2020), we opted for data entry in a spreadsheet. Five tables were created in an Excel spreadsheet to represent Sites & Structures (E27/S20), Objects (E19), Research Activities (S4), Stratigraphic Units (A8) and Documents (E31) that were explicitly or implicitly referenced in the documentation.
The manual assignment and management of identifiers was critical to link the entities to each other, especially as these appear in various source documents. As mentioned above, the linking from concepts to the Thesaurus created in Section 3.3 was achieved using a concept@identifier string. To create 1:n relationships, several concepts or identifiers had to be linked to one entity (like a site, structure or find). In order to do this, a separator (in our case '|') was used, allowing more than one concept or identifier in the corresponding cell. Therefore, the structure of a relational database can be re-created in the tables. n:m relations can be represented with this structure as well as making the editing and viewing easy. A drawback of this data entry methodology is that the possibilities to control the entry are limited, whereas the advantage is that there is no need to develop a database interface for data entry and that information can easily be copied into many cells, thus enabling quicker data entry. Figure 8 shows the sheets for Sites & Structures (E27/S20), Objects (E19) and Stratigraphic Units (A8), indicating how identifiers relate to other sheets.

The Excel sheets described in the previous section together with the files of the Thesaurus creation were imported into a Postgres database. The next step was to apply specific transformations to the data, executed with SQL scripts. Where necessary, information from different sheets were linked together through the identifiers. The third task in the database was the creation of URI identifiers which are necessary for the RDF creation. These were generated in specific 'uri' tables.
For the thesaurus the file containing the concept hierarchy that was exported from the mind map was transformed to an id/parent_id structure, allowing the RDF creation process to be independent from the hierarchy depth of the thesaurus. In the 'RDF Creation pipeline' handbook there are links to the SQL scripts for the transformations (see Section 5).
The 'uri' tables created in the Postgres database are the input for the RDF creation. Various tools may be used for this step like Karma, OntoText-Refine or the X3ML toolkit (Theodoridou and Kritsotakis 2022). As we directly accessed the relational tables in the database we used Ontotext Refine and stored the triples in an Ontotext GraphDB triple store. The ontologies and the prefixes have to be loaded into a repository of GraphDB, in order to support the process of creating the mapping that was defined in Section 3.2.
To create ARIADNE aggregation data, additional information specific to the ARIADNE Catalogue had to be entered in an additional 'ADRIANE Metadata' Excel spreadsheet and a mapping to the ARIADNE ontology - the AO-Cat – (Felicetti et al. 2023) was performed to create the RDF necessary for the ARIADNE portal. One of the challenges to reusing the network previously described was the fact that the ARIADNE portal uses their own URIs, which are specified and only the last part is optional definable. The ARIADNE Team, who supported us very much in the process, recommended that we create the ARIADNE URIs in the Postgres database through a hash function of the original URIs. The RDF creation pipeline including the 'ARIADNE Metadata' Excel spreadsheet is illustrated in Figure 9. It shows the process from Excel sheets/Thesaurus over the postgres database to the RDF representation in the triple store.
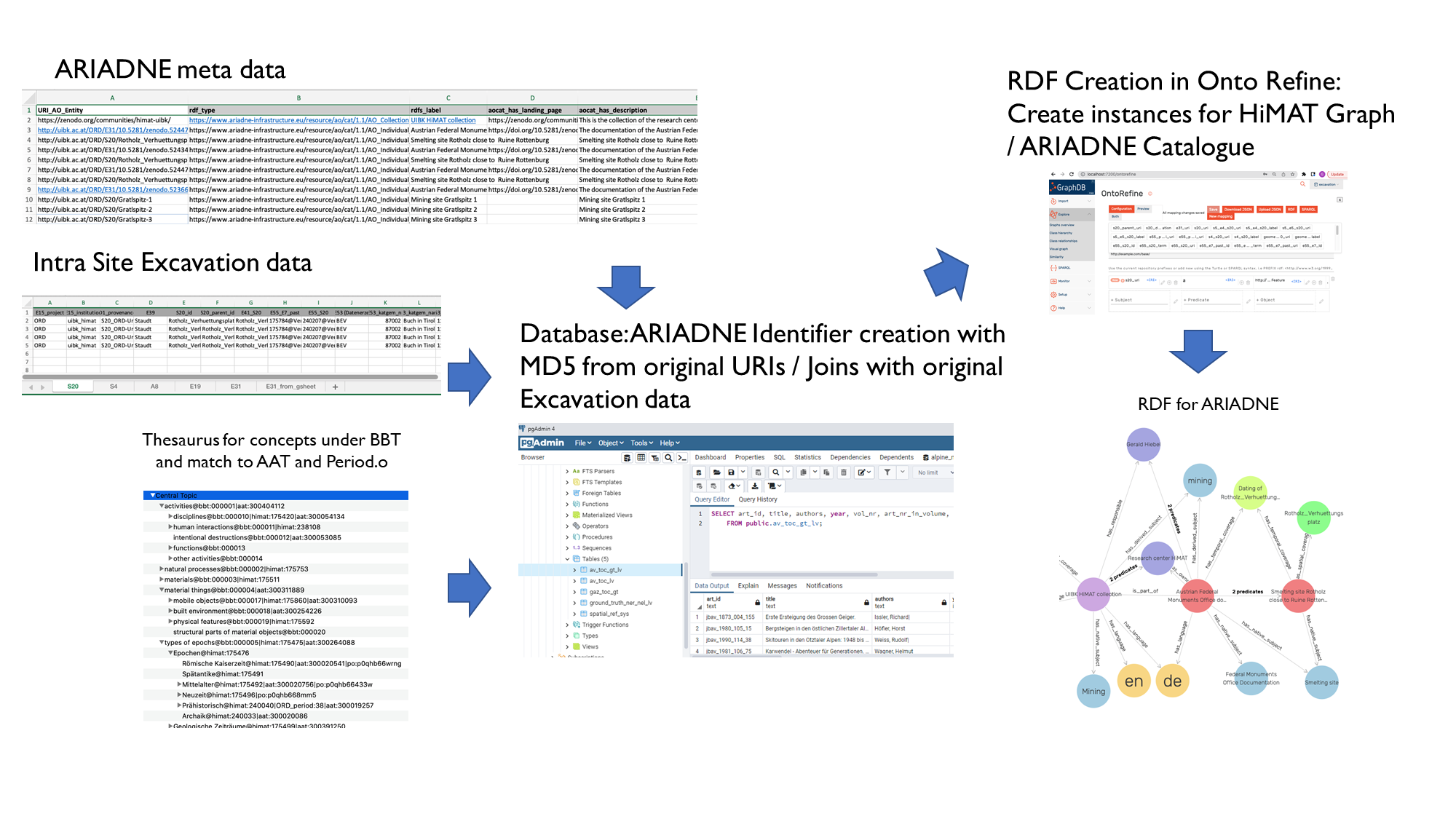
This strategy allows the re-creation of the same ARIADNE URI from original URIs. In the ARIADNE portal a collection was created for the prehistoric mining sites in the Lower Inn Valley processed in the Open Research Data Pilot project (ORD) of the University of Innsbruck (UIBK). In the collection the different Federal Monuments Office documentations are represented as 'Fieldwork archive' with a link to the zip file deposited on Zenodo. The sites documented in the Fieldwork archives are represented as 'Site/monument' and link to the Knowledge graph of the Research Center HiMAT. In the knowledge graph it is possible to navigate to the links on Google Drive of the single folders/documents related to a specific site/trench/stratigraphic unit or find. Both options are illustrated in Figure 10. Of course it is also possible to query the graph with SPARQL to retrieve the links to the documents. In the collection there are only 18 records but through the links to the knowledge graph many more detailed records of the sites are available. The goal is to apply the pipeline to other archaeological research at the University of Innsbruck.

In the course of the project a handbook has been produced (Figure 11) detailing the methodology and providing sample data so that anybody interested can walk through the examples and create RDF data using the tools and data (Hiebel and Peralta Friedburg 2023).

Currently there are sample data for three different datasets:
The structure is the same for all three, corresponding with the numbering in the handbook:
5.1 Create utf8 tab-delimited structured data from a spreadsheet or from a database
5.2 Understand your data and create a conceptual model based on CIDOC CRM ontology
5.3 Load data into Postgres
5.4 Transform data & create URI identifiers (and labels) for concepts in Postgres
5.4.1 Transform data
5.4.2 Create URI identifiers
5.5 Import in RDF creation software (Ontotext Refine)
5.6 Create conceptual model or apply existing model
5.7 Publish RDF to triple store (GraphDB)
For all three datasets there are folders and files as illustrated in Figure 12.

In this article we have shown how the Austrian Federal Monuments Office documentation for the project 'Prehistoric copper production in the eastern and central Alps' was transformed to create FAIR data and a knowledge graph in RDF using the CIDOC CRM ontology with extensions. The same methodology was applied to create RDF data using the ARIADNE ontology for the ARIADNE portal. The methodology section outlined the process of RDF creation and pointed to a detailed 'RDF Creation Pipeline' handbook that should make the steps repeatable. The aim of the handbook is to give others the ability to apply the methodology to their own data. Understanding of data structures and skills in data modelling with CIDOC CRM and SQL will be necessary but no programming knowledge is needed to perform the tasks. An understanding of the ARIADNE ontology is necessary to apply the pipeline in order to create the RDF for the ARIADNE portal. Sample data and modelling patterns for ARIADNE data creation are not yet included in the 'RDF Creation Pipeline' but are planned to be included in a subsequent version of the handbook. Creating ARIADNE data helped us to see what was still missing in the original data creation process. As it was the primary provenance that was not sufficiently captured and modelled, a desirable goal for future RDF generation is to include the necessary data in the modelling and create ARIADNE data simultaneously. We are currently exploring the use of named graphs and reification constructs like RDF-star to model provenance and also represent proposition sets like inferences. The Austrian Federal Monuments Office documentation of the archaeological investigations that have been carried out in the project 'Information Integration for Prehistoric Mining Archaeology' are currently being processed and will be included in the HiMAT knowledge graph as well as the ARIADNE portal.
The research presented here was financed by the Austrian Science Fund (FWF) in the course of the Stand Alone Project 'Information Integration for Prehistoric Mining Archaeology' (FWF, P 31814-N38) and the Open Research Data Pilot funding schema with the project 'Mining, Technology and Trade in Prehistory - Open Data from Prehistoric Mining Archaeology' (FWF, ORD 74-VO). Federal Monuments Office documentation was created in the trinational joint project (DACH) 'Prehistoric copper production in the eastern and central Alps' (FWF, I 1670-G19).
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service. Help sustain and support open access publication by donating to our Open Access Archaeology Fund.
 Home
Home