A large number of algorithms are available to 'process' geophysical data. It is therefore useful to investigate carefully which data are used, and what processing is possible and necessary. A differentiation into three categories has proved to be useful (see Fig. 1).
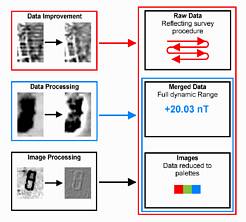
Figure 1: Three different categories of data processing, requiring corresponding levels of detail in the data
Data Improvement: Where information on the method of data acquisition is available, common data acquisition problems can be rectified with appropriate algorithms. For example, data collected while walking up and down a field ('zigzag') sometimes show staggering ('shearing') between adjacent lines, due to misalignment of the operator with the predefined grid. If the length of individual survey traverses and the order of zigzag lines are known, the problem can be partly corrected. Such processing can only be applied if data are available in a format that reflects the surveying procedure (e.g. if data are saved as separate grids) and if information on the surveying strategy is given (e.g. 'zigzag lines within each grid, starting in the NW corner'). Other examples of data improvements include zero-drift correction and grid balancing.
Data Processing: Where the full dynamic range of measurement values is available, processing algorithms can be applied that are suitable for the particular geophysical technique used (e.g. reduction-to-the-pole for magnetometer data or high-pass filtering of earth resistance data to bring out small scale variations; Fig. 2). To avoid problems at the boundaries between individual sections of data (grids) they are often merged into one single 'composite' before such processing is carried out. It is essential that information on the spatial dimensions of the data (e.g. resolution) is available and for combination with other data sources the coregistration of the geophysics grid system is required.
Image Processing: When data are converted into images for display purposes, accurate spatial information is often lost and the full range of data values is compressed to the limited resolution of a palette that suits a particular display best (e.g. 256 shades of grey). These pictures can then only be treated with standard image processing tools that do not take into account the geophysical nature of the underlying data. A typical example would be 'embossing' or 'blurring' that can create pleasingly looking pictures that have, however, limited analytical use.

Figure 2: High-pass filtered earth resistance data from the courtyard of a Buddhist monastery at Paharpur, Bangladesh. (a) Raw data and (b) filtered data showing the buried remains of two walls (i) and processing artefacts (ii) and (iii)
There have been various advances in 'data improvement' techniques, for example the development of sophisticated destaggering methods (Eder-Hinterleitner et al. 1996), but the following will focus on 'data processing' as defined above. The main purpose of such processing is the discovery of information that is encapsulated within the data but cannot be 'seen' if they are displayed in a conventional way. In some cases, more imaginative visualisation techniques will bring out subtle features (e.g. animation, see below) and sometimes the inspection of different clipping ranges is sufficient to gain new insight (Vernon et al. 1999). However, suitable processing is often the only way to discover relevant archaeological anomalies. A good example is high-pass filtering where a background (presumed to be a geological 'trend') is removed from the data to reveal small-scale features, which are taken as the desired archaeological remains. However, such filtering introduces new artefacts into the data, most notably halos around confined anomalies (see Fig. 2). It is hence of paramount importance to be aware that such signatures are caused by the inherent properties of a particular processing technique and are not 'real'. The danger is obvious: when the processing is more complex and the whole algorithm is seen as a 'black box', it becomes difficult for the user to distinguish between archaeological anomalies and processing artefacts. Modern software packages fortunately offer large numbers of processing functions (Schmidt 2001) but if applied in random order by a novice user they can produce meaningless results. Comparison with the original measurement data is, therefore, always recommended and some authors suggest it is better to minimise processing altogether (Gaffney et al. 1991) by collecting data of the highest quality in the first instance.
© Internet Archaeology
URL: http://intarch.ac.uk/journal/issue15/9/as9.html
Last updated: Tue Jan 27 2004