
While this is a serious issue, there is a deeper, potentially more harmful, ethical problem posed by our research. Our project is also trying to use computer vision to understand the visual tropes present 'behind' the online trade. It is often quite clear that what's going on in the image is not what is being officially stated in the comments. How do we assess these data at a scale that enables us to understand what's going on? If we get it wrong we run the risk of creating a system that could be used to authenticate remains as belonging to a particular people or group, thus enhancing the saleability of the remains.
We have been using convolutional neural/neuron networks, a technology that mimics the way the eye and the brain makes sense of an image (the critical paper of Krizhevsky et al. 2012 launched the current boom in neural network approaches to images; see also Schmidhuber 2015; Witten et al. 2017). CNN (convolutional neural networks) is currently the state-of-the-art for image recognition. For an accessible overview of the field, see T.B. Lee 2018; for an accessible discussion of the mechanics and workflow of using CNN (in this case, in the context of identifying dada poems visually within the pages of literary magazines), see Thompson and Mimno 2017. The algorithm converts the information in the image, the colour values of the pixels, into a series of present/absent evaluations. It pans across the image performing a series of these evaluations (convolution) where each calculation is sensitive to a different kind of arrangement of pixels. These values are passed up (or not) to another layer such that each successive layer responds to more complicated patterns or shapes. By analogy with the brain, each layer is imagined as a series of connected neurons. Each neuron responds to a different aspect of an image and all of these layers activate in different weightings of connections. The combination of those weightings allows for the identification of what's going on in the image. The result is a mathematical representation (a 2048 dimensional vector) for every single image. In automatic image captioning, the final layer of neurons is used to assign the labels. Here, we look at the second to last layer, which is the vector representation of the image, and use t-SNE (t-Distributed Stochastic Neighbor Embedding) or other kinds of clustering algorithms to achieve 'dimensionality reduction' and find patterns of similarity within the images (van der Maaten 2014; van der Maaten and Hinton 2008). This gives us a macroscopic view of all of the (machine-visible) patterns inherent in the tens of thousands of images collected (see Huffer and Graham 2018 for a detailed discussion of the approach as applied in our research).
So far, so ethical: the machine vision is merely reporting back patterns in the imagery, where similar patterns of neuron-coactivation are used to guide our reflection on the material. If we are 'methodological individualists', i.e., we believe that only humans are capable of moral actions, then there is no ethical problem with machine vision, only in how we use it. If, on the other hand, we take the view that the algorithms of machine vision are an extension of our ability to act, then the moral responsibility for what results is both with us and with the machine (Hanson 2009, 92). Risam argues that we have to be attuned to the ways that many of our digital tools represent white, male, Global-North ways of knowing, in that the 'human' imagined as the test case for achieving human-levels of acuity in image recognition is the same kind of human most often responsible for the design of these algorithms (Risam 2018, 124-36). In which case, we have not only to examine the results of the usage of these technologies, but also how these technologies work and to what their attention is attuned. Hanson argues that the moral force in situations where there is joint responsibility, human and machine, also depends on the degree of harm that can be accomplished (Hanson 2009, 97-8). For machine learning of the kind described in this article to work, it needs a corpus of reference materials to learn from. Amazon famously created an 'artificial intelligence' to help sort candidates for jobs that learned from its training data the biases of Amazon's HR department towards male candidates (see, for instance, Reuters 2018). Similarly, a company called Predictim has released an application that assesses potential babysitters from a variety of social media to determine their trustworthiness to work with clients' children (D. Lee 2018), just one such application of many. In this latter case, the founders of the company demonstrate a profound lack of awareness that the choice of reference materials embodies their own priorities, privileges, and perspectives on what constitutes a suitable candidate, with all of the racial and other systemic biases that exist with this legal 'grey area' (Merrillees 2017). In which case, we need to ask, what, and how much, harm can our research accomplish?
Training a neural network model on a corpus of images, from scratch, is massively computationally intensive, requiring millions of images in order to be successful. The Inception3 model from Google was trained on the ImageNet corpus, which manually paired hundreds of thousands of images against the Wordnet hierarchy (Szegedy et al. 2014, Krizhevsky et al. 2012). For all its success at identifying and captioning images, it does not recognise human remains at all, for these were not part of the training corpus. However, we can use the techniques of 'transfer learning' to take this model and tweak the final few layers of it with new information that we want it to learn. We feed it mere thousands of images organised and categorised for our target subject matter, which functions as a kind of tuning so that the neural network model will identify these new - and only these new - categories. If a researcher defines a corpus as containing 1000 images of human remains from the Huron people and 1000 images from Dayak individuals, after transfer learning the machine will duly find that every unknown image represents some combination of Huron and Dayak human remains.
Whether or not the labelling is correct is conveyed by a probability estimate, but remember, it is not the probability of whether or not the image depicts X or Y; it's the probability that X or Y matches the aggregate characteristics of the images collected in the training data in the first place. It could well be that the classifier has picked up on some subtle bias in that original data - perhaps the images for the first category all have a particular backdrop, a texture in the wood platform supporting the remains (a function of what the photographer had handy that day) while the second set of images were all taken through museum vitrines.
Recent research has worked to develop ways of knowing just what the neural network is responding to. Packages such as Keras-Vis can be used to determine what the machine is actually looking at (Kotikalapudi et al. 2017). An online demo of a similar package that allows one to upload an image and visualise the parts of an image that the neural network is responding to is also available (Selvaraju et al. 2018). When we upload an image of a toy Hallowe'en skull, the resulting visualisation shows that the machine's attention is focused on the nasal bones and one of the orbital cavities (see Figure 1; the colourful pixels or the areas of light show the areas that activate the neural network most using various algorithms). Another photograph of the same skull sitting on a metal table with a strong reflection changes the machine's focus more to the orbital bones, and the network assigns a completely different label (Figure 2). (An approach released by Google, Kim et al. 2017, is also a possibility and promises to identify 'high level concepts' that the network is identifying, but evaluating this claim in our context will require further research.)

Another approach that can be used to determine what the machine is actually 'seeing' is to set two neural networks in opposition to one another - so-called 'generative adversarial networks'. In this approach, one network plays the role of the 'detective', and the other network plays the role of the 'forger'. The 'detective' network is our standard neural network for identifying images, while the 'forger' network feeds images that it creates itself to the detective. The detective network is fed several thousand images, against which it compares the forger's image. When the detective determines that the forger's image does not match in particular ways, that information feeds back to the forger which makes subtle alterations. In this back and forth, the forger network eventually begins to produce images that the detective accepts as 'authentic' images. If we then study those images, we can learn something of how the original network 'looks' at images (an approach suggested to us by Wevers, who has used this approach to study the evolution of automobile advertising in newspapers, Wevers et al. 2018).
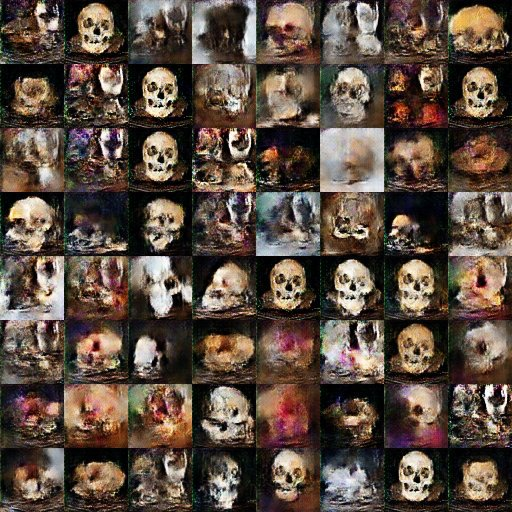
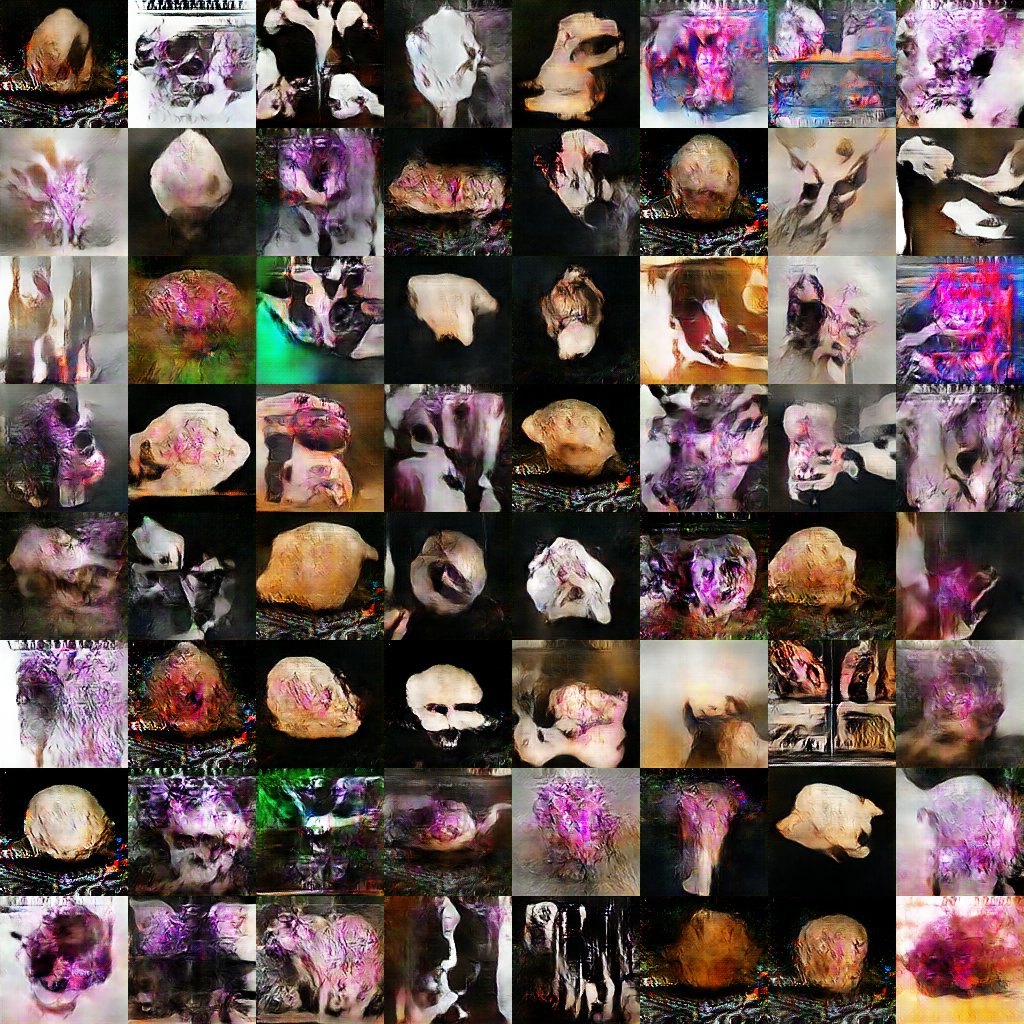
In Figure 3 and Figure 4, we see the result of training an adversarial network on 1500 images downloaded from Instagram under the tag 'skulls-for-sale'. We used Gene Kogan's version of Taehoon Kim's code for a tensorflow implementation of deep convolutional generative adversarial networks, which has been modified slightly to enable it to run on the paperspace.com cloud machine learning platform (see Kogan's class notes and video lecture, 'Generative Models', 23 October 2018). The result resembles a gallery of paintings of memento mori. While striking, and it is important to reiterate that these are not human remains but the machine's understanding of what skulls look like, this information with its numerous near-duplicates shows us that the network has not been trained on a large enough corpus. It has identified a series of nearly similar images from the same Instagram user as being most representative of the sample and so generates many slight variations of that picture. On a larger dataset of 6700 images tagged with 'skull for sale', the resulting image produces nightmarish concoctions of what seems to be manipulations of nasal bones, orbital sockets, and brain pans. The reader will also note strange areas of pink and purple in many of the images. By re-viewing the original data, we believe that what the machine is seeing in this case (and thus, generating as a key signal to defeat the 'detective' network) are texts that have been overlaid on the original image saying 'for sale!' and phrases in that vein. Note that the associated post metadata and comments do not indicate anything for sale; putting the text into the image would seem to be an attempt to avoid scrapers and crawlers.
In an experiment using CNN against X-rays from three different hospitals to diagnose disease, the researchers found that the CNN were picking up signals specific to the individual hospital systems. That is, the CNN learned what an X-ray from a portable machine looked like - and since portable X-ray machines are typically used in cases where the patient is already very sick and cannot be moved readily, images from portable machines tend to have a much higher rate of positive diagnoses. The CNN then learned not what the signals of disease were in the X-ray, but that X-rays sourced from a particular kind of machine signal disease (Zech 2018; Zech et al. 2018). When we collect images from social media posts, we have to be attuned to the fact that the neural network might be picking up signals that have little to do with the ostensible subject of the photo. Archaeological users of neural network approaches to data need to be alert to and investigating the confounding information, and to work out what this is doing to how the computer sees or makes sense of the data. (Indeed, this is an active area of research in computer vision, with some results suggesting that the majority of the CNN algorithm's performance accounting for its accuracy seems to be correlated to low-level noise in the images, rather than in the more complex signals, Brendel and Bethge 2019.)
This applies to transfer learning as well: what extraneous signals are we introducing to our training dataset? Once the re-trained model is deployed in an app, the model acts as a black box, with no realistic way to know just what signals are being perceived. The resulting app carries the appearance and authority of 'machine learning', where we end up with an 'official' result: 88%
We will have committed, in effect, an act of digital phrenology that enhances the violence already meted out to these individuals through removal from their place of origin, subsequent modification, trafficking, and transformation into a commercial object. The alleged ethnographic, historic or archaeological human remains observed being bought and sold online, if not in fact 'forged' cultural heritage made using unprovenanced crania possibly obtained from modern open-air or subterranean cemetery looting, would therefore have been collected or stolen in the late 19th century or early 20th century. Collecting such material was often done for purposes of curiosity, to further the cause of 'scientific racism', or as evidence of colonial power as Western missionaries, government officials, and early practitioners of physical anthropology sought to 'discover', define, and categorise the world's people (with white people at the top), and build anatomical teaching collections (e.g. Redman 2016; Roque 2010; Sysling 2016).
This technology is also being deployed by, for example, IBM and the NY Police Department to obtain stills of individuals caught on closed-circuit TV footage and label the images with physical tags, such as 'ethnicity' or clothing colour, to allow police to search video databases for individuals matching a description of interest (Joseph and Lipp 2018). It is also being used in China to further marginalise the Uighur people and create 'social credit scores' in a system of constant surveillance (Samuel 2018). Is it ethical for human remains trade research to employ the same technologies that are being deployed against basic human freedoms? An even more direct analogy is the increasing use of AI to detect child abuse images online, such as iCOP (Clark 2016; Tarantola 2016). The major association of computing, the Association for Computing Machinery (ACM) has recently redone their code of ethics (2018) to foreground doing no harm (ACM 2018). How can our project contribute to human well-being both for the living and the dead while avoiding participating in this future harm by, for example, flagging other uses of human remains imagery or resin replicas displayed online as part of an individual's art, or by practising bioarchaeologists, anatomists or Catacomb historians disseminating their legal, publicly funded research to new audiences in a digital realm (e.g. Huffer 2018; Eubanks 2017)? Should our codes of conduct and of ethics in archaeology and osteology explicitly deal with these issues and, if so, how?
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service. Help sustain and support open access publication by donating to our Open Access Archaeology Fund.